


The last weekend of January 2026, I went to the NVIDIA DGX Spark hackathon at Antler in San Francisco. The project was a Palantir-style harness for SF residents to analyze public government data, with a small model that we trained on the Spark and intended to serve from it. The hardware was a Dell Pro Max with the GB10 chip: DGX Spark class, SM121a, the first piece of consumer Blackwell I’d touched.
It mostly didn’t work. pip install vllm and serve was not a thing you could do. flash-attention didn’t import. Triton crashed on Python 3.13. The workaround at the hackathon was “we’ll just cloud it,” which was fine for a weekend and not fine for a product.
A few weeks later I joined Second Nature Computing, where the Spark sits squarely on the roadmap: training, fine-tuning, and inference all run on this hardware for the product. That made the “we’ll just cloud it” workaround a non-option. Every open-source piece that didn’t work on SM121a was a piece of our stack that didn’t work. The week of February 9 I started looking at the failure points one at a time, intending to file fixes upstream.
What followed was four months of upstream contribution work across six repositories: SGLang, FlashInfer, flash-attention, vLLM, CUTLASS, and Triton. The short version of the outcome: the foundational SM120 attention kernels (forward, backward, varlen) are merged and are now what the broader ecosystem builds on; roughly a dozen more dispatch and correctness fixes landed across the six repos; a few PRs were closed, some by maintainers and some by me after a closer look showed the fix wasn’t right. This post is the engineering tour, the parts that worked and the parts that didn’t.
A companion inventory report catalogs every PR, reviewer, and days-to-merge metric. This is the narrative cut.
The first PR I got wrong
The first PR I opened as blake-snc was sglang#18748 on February 12, 2026. The title was “Add SM12x to FA4 compute capability whitelist.” DGX Spark hard-crashed when sgl-kernel’s FA4 interface checked _get_device_capability(), saw major=12, and asserted because the allowed list was [9, 10, 11]. My fix added 12 to that list.
b8zhong, an sglang maintainer, replied five minutes later with one line:
I don’t think SM120 supports FA4?
I doubled down. I posted a detailed reply asserting that FlashAttentionForwardSm100 “uses the Blackwell-wide tcgen05 instruction set, which is common to all Blackwell variants,” and cited CMakeLists fragments that built SM120a alongside SM100a, the existence of FlashAttentionForwardSm100using tcgen05 atoms, and the fact that SM110 already worked through the same path.
This was wrong, and wrong in a way that mattered. I had asked an LLM to validate the assumption that “Blackwell is Blackwell,” and it confidently agreed with a story that wasn’t true. The evidence I cited looked supportive only if you read the surface layer. None of those facts establish that SM120 supports tcgen05, which is the only thing that determines whether FA4 will run.
b8zhong replied an hour later:
That’s not correct. SM120 doesn’t have
tcgen05… If you want to use LLM to answer the question, I just recommend cloning repo like cutlass so it can better explain what instruction is actually supported.
That correction is the part of this story I think about most. The technical fact, that SM120 lacks tcgen05, was something I should have verified before opening the PR. The bigger lesson was the verification method. I had been asking an LLM to summarize. The fix was to read the source.
I cloned CUTLASS, opened cute/arch/config.hpp, and found CUTE_ARCH_MMA_SM120_ENABLED gated on SM120F/SM121F, with no CUTE_ARCH_TCGEN05_* defines and no TCGEN05_TMEM_ENABLED. SM120 gets the warp-level MMA path. SM100 gets the CTA-level tcgen05 path. They are different hardware sharing one marketing umbrella. The “Sm100” in FlashAttentionForwardSm100 is not a stand-in for “Blackwell.” It is literally SM100, built on tcgen05.mma plus TMEM throughout, and SM120 physically does not have those instructions. (The architecture split has since been documented independently more than once; backend.ai’s teardown and gau-nernst’s tcgen05 walkthrough both reach the same conclusion.)
I closed #18748 with a walk-back that thanked b8zhong for catching it before it shipped, and wrote the architectural diff into the close comment. Accepting the correction quickly, rather than arguing or quietly deleting the PR, is probably what made the next dozen sglang interactions productive instead of adversarial. b8zhong reviewed several of my later PRs.
The takeaway was bigger than one PR. I ran a focused grep across the stack (flash-attention, FlashInfer, vLLM, SGLang, CUTLASS, Triton) for arch-version checks. Every literal == 120, not in [89, 120], or if major == 10 was a candidate failure for SM121a, which has major=12, minor=1 and falls through every exact-equality check written for SM120. I counted roughly twenty across the six repos. The thing I needed to fix wasn’t one whitelist. It was a pattern.
What “broken” actually meant, repo by repo
Once the pattern was visible, the broken state of consumer Blackwell on each repo organized itself into specific failure modes:
flash-attn —
pip installsucceeded but the SM120 forward kernel was absent; the Python dispatch asserted on the first call. No backward, no varlen, no paged KV.flashinfer — FA2 worked. FA3/FA4 dispatch crashed when hit. The BF16 XQA MLA decode kernel (
mla_sm120.cu) compiled and ran but produced 100% NaN output. DeepSeek prefill whitelisted SM100 only.vLLM — Marlin and CUTLASS FP8 dispatch excluded SM121 because of a
NamedTuplequirk (more below). The Qwen3.5-MoE backend wasn’t wired in. The flash-attention loader didn’t try the cu130 wheel.SGLang — the runtime preloader searched for
libcudart.so.12; DGX Spark shipslibcudart.so.13. sgl-kernel’s dispatch was exact-match== 120so SM121 fell through. Error messages said “Blackwell (SM100)” without distinguishing SM10x from SM12x.CUTLASS — no CuTe DSL Flash Attention kernel for SM120.
MmaSM120BlockScaledOprejected SM121 with an exact-equality guard, and the same pattern repeated in the SM90 warpgroup path.Triton —
@aggregate-based JIT APIs crashed at trace time on Python 3.13, specifically on PEP 649’s deferred annotation evaluation.
Some are one-line whitelist additions. Some are kernel rewrites. None had been visible to anyone testing on SM90 or SM100. As far as I could see in the trackers in mid-February, nobody had systematically tested most of these on SM12x.
The work that followed turned most of that red to green. The image below is the honest scorecard, start of February versus now:
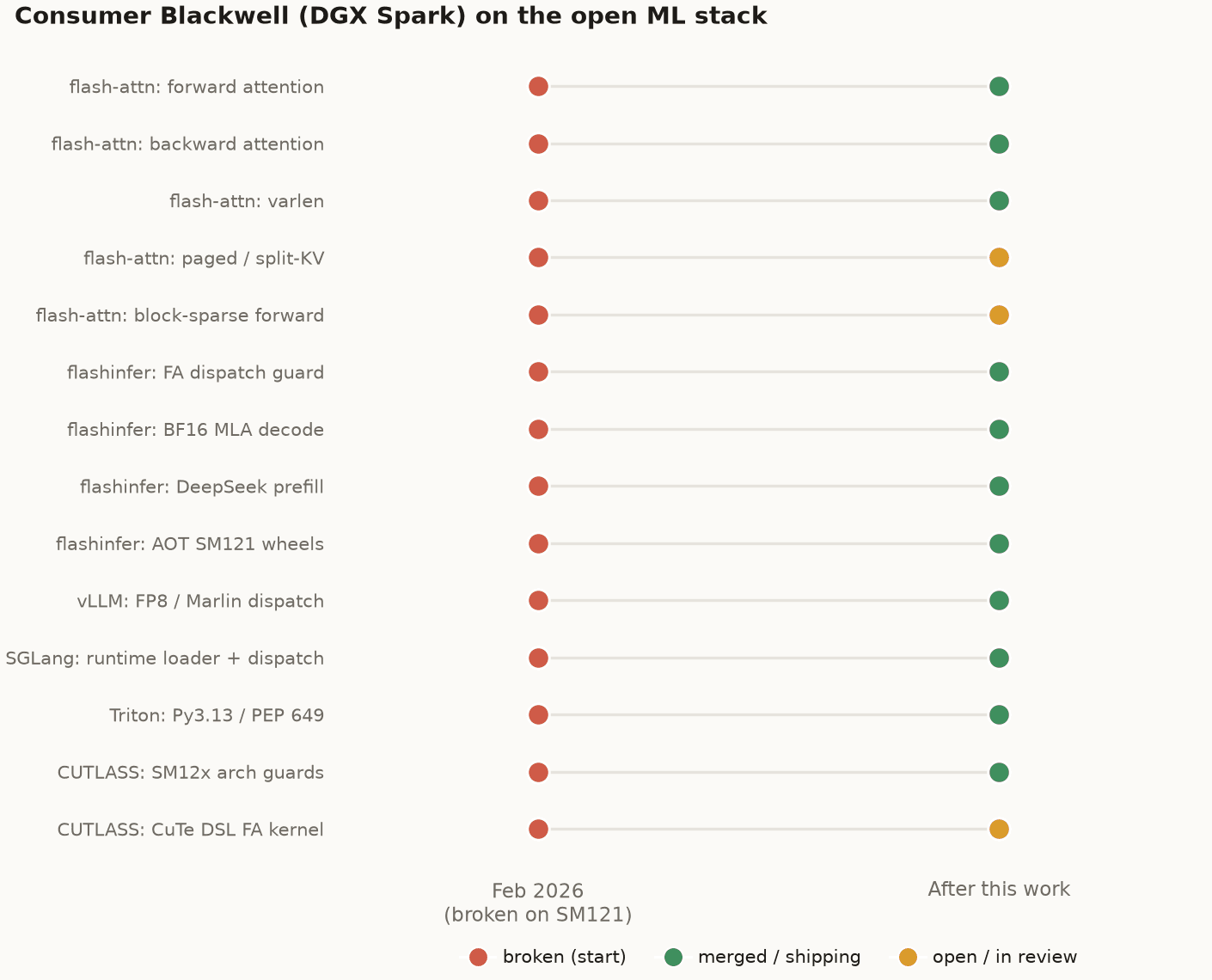
Consumer Blackwell (DGX Spark / SM121) support across the open ML stack, February 2026 versus after this work: most capabilities went from broken to merged or shipping, with a few still open in review.
Phase 1 — the dispatch layer (February)
The first month hit the layer where being wrong was cheapest: dispatch checks, whitelists, runtime loader paths, error messages. February ran as three overlapping waves (SGLang, FlashInfer, CUTLASS), not as sequential phases.
SGLang dispatch (#18747, #18750, #18751). The same night #18748 closed, I filed three SGLang fixes that didn’t repeat its mistake. #18747 made _preload_cuda_library() detect torch.version.cuda and try the matching libcudart.so.X (and route the install hint to the cu130 wheel index). #18750replaced an exact-match == 120 with >= 120. #18751 changed the user-visible error string from “Blackwell (SM100)” to “Blackwell (SM100/SM12x)” so SM12x users hitting the mismatch don’t have to wonder whether their device is the problem. Three days to merge each; the SGLang maintainers have a tight cadence on small, focused fixes.
Two more from that batch, #18754 and #18755, I closed within hours of filing once #18748’s correction made me re-read what they actually did (same tcgen05 misread, and an MXFP8 path that needed a real SM120 kernel rather than a whitelist add). The close comments, with citations, are there for anyone hitting the same walls.
There was also #18758, a larger umbrella PR meant to route SM12x to flashinfer-based backends. I made the same class of mistake one more time, at a larger scale: it grew sprawly across five files and several subsystems, and b8zhong closed it on March 2 with a note that it looked AI-generated and that one piece (allreduce fusion) depends on P2P, which SM120’s topology doesn’t support. His read was fair. The lesson that stuck was to stop bundling: one focused PR per logical change, even if it means more PRs. The correct individual pieces went forward separately later.
FlashInfer dispatch (#2559, #2560, #2574, #2654). Calmer waters; the FlashInfer maintainers had been thinking about SM12x more carefully than I’d realized.
#2559 (merged by jimmyzho, six days) un-gated DeepSeek prefill, which compiled and ran correctly on SM121 once called.
#2560 (merged by jimmyzho, 28 days) did two things: guarded CUTLASS FMHA against routing SM12x to FA4/tcgen05 paths (the exact failure b8zhong had warned me about), and fixed an exact-match SM120 check missing SM121a. The guard needed care because the codepath is shared with SM100 and the fix had to not break SM100 routing.
#2574 (merged by yongwww, eight days) replaced six inconsistent “is this SM12x?” call sites with one
is_sm12x_supported()helper. Nobody is excited to review a mechanical refactor, but it’s the kind of fix that keeps the next contributor from filing the next#18748.#2654 (merged by yzh119, three days) added SM121 to the AOT compilation modules. The JIT path already dispatched SM121 to SM120 modules; the gap was that AOT-prebuilt wheels didn’t include the SM120 fused_moe / gemm / fp4_gemm modules at all.
First CUTLASS PRs, and a contribution pattern worth naming. Late February I filed cutlass#3082 (add sm_121a to MmaSM120BlockScaledOp.admissible_archs) and cutlass#3084 (the SM90 warpgroup guard). On April 28, NVIDIA’s depaulmillz commented on #3082:
There will be a fix for this in the next 4.5-wheel release.
That changed how I think about the NVIDIA-managed repos (CUTLASS, TensorRT-LLM, cuDNN samples). The fix goes through an internal tree and ships in a wheel; the public PR often closes without a merge. The PR is the bug report; the wheel is the fix. After that I treated #3082 and #3084 as filed-and-acknowledged. (#3082 did close in June, once main carried the equivalent change.) The larger CUTLASS kernel, #3030, is a different story, below.
Phase 2 — the SM120 attention kernels (March)
This was the layer that mattered most, and the part I’m most willing to call a win. The dispatch work made the stack stop crashing. The kernel work made attention actually run on the chip, and it’s the foundation the rest of the ecosystem now sits on.
I’d first filed flash-attention#2268 as a monolithic SM120 PR. tridao asked for it to be split, which produced a cleaner three-PR history:
#2329, SM120 forward. A
FlashAttentionForwardSm120class on the SM80 base: CpAsync (no TMA),m16n8k16/m16n8k32MMA, and tile sizes re-budgeted for SM120’s 99 KB SMEM (the SM80 base assumes ~64 KB, SM90 has 228 KB; neither fit). Settled onm=128,n=64for D=128,m=128,n=128for D=64, validated against PyTorch SDPA with max_diff under 0.02. Filed Mar 11, merged by tridao Mar 12.#2330, SM120 backward. The interesting part was the dQ accumulation, which is shared across thread blocks and needs atomic writes. The NVVM
atomicrmwpath the SM80 kernel generated wasn’t accepted by our toolchain’s bindings, so I replaced it with inline PTXred.global.add.f32, which emits the sameRED.E.ADD.F32SASS. dQ accumulates in FP32 in shared memory before the global atomic, so rounding stays bounded. Filed Mar 11, merged Mar 12.#2333, varlen. The notable moment was a padded-offset bug: the preprocess kernel defaulted to
tile=128while the backward usedtile_m=64, sopadded_offsetdisagreed between the two sides (preprocess zeroed dq_accum at offset 256, backward wrote at 192). Tests passed in isolation because fresh memory was clean, and failed in sequence because CUDA’s allocator reused NaN-polluted memory. compute-sanitizer showed zero errors because the addresses were valid, just wrong within the buffer. The fix passedtile=self.tile_mso both sides agreed. Filed Mar 12, merged Mar 13.
Three kernels, three one-day merges. Those three PRs are the thing I’d point to first.
A few days later, johnnynunez found bugs in them. johnnynunez, an NVIDIA researcher at the Jetson AI Lab, filed #2420. The main one: FlashAttentionForwardSm120 sets self.arch = 120, then super().__init__() clobbers it back to a placeholder, so a later arch >= 90check took the wrong branch and tried to use TMA-O output store, which SM120 lacks. The fix was setting self.arch after super().__init__(). He also caught a couple of None-tolerant config variables missing from the backward struct. This is the class of bug that’s obvious in review and impossible to see without running on the hardware, which is exactly why a second person on the actual chip is worth a lot. Johnny was migrating NVIDIA’s Isaac GR00T to FA4 in parallel, so our consumer-Blackwell concerns overlapped; he reviewed by reproducing the failing config, pasting the output, and proposing a fix in the same comment, and he kept tridao’s review context warm, which is part of why some of those merges were one-day.
When CUDA 13.2 shipped in early March, Johnny DM’d me the SM12x-relevant items the same day: cuBLAS MXFP8/NVFP4 GEMM up to 3× on DGX Spark, a BF16/FP16 illegal-memory-access fix that explained some random crashes we’d been logging, CCCL TMA codegen improvements, and a CUTLASS SM120 pingpong fence fix. We didn’t fold most of that into the merged PRs, but it helped triage the open ones.
Phase 3 — the harder kernels (March–April)
After the trio merged, the work shifted to kernels the production stack needs but that take more reviewer time per PR. These are open:
#2336, split-KV (FlashDecoding) with FP32 partial outputs. The numerically interesting call: SM90 can use FP16 partials and combine at the end, but SM120’s 99 KB SMEM can’t fit the FP16 partial buffers across splits, and FP16 caused observable drift in the combine step on long sequences, so FP32 partials were required for correctness.
#2348, paged KV. Uses non-TMA scatter/gather, because TMA’s contiguous descriptors can’t express per-page address computation; you do the page-table lookup in code and
cp.async.cg.shared.globalthe transfer.#2349, TMA forward with warp specialization (one DMA warp, three MMA warps), with a
can_implementfallback for hdim>128 where register budget would spill.#2389, SM80/SM120 block-sparse forward. (Actively moving as of this writing, more in the June note.)
Dropout (#2439). #2439 came from Johnny’s issue #2436: GR00T needed dropout in CuTe DSL, and tridao had noted the philox PRNG handling makes it nontrivial. The philox mask has to match between forward and backward for a given (row, col), and the seed has to be position-derived because backward uses a different thread partition than forward. My first draft seeded from thread_id. It compiled and produced a different mask in backward, so the gradient was wrong in a way that looks fine on short sequences and drifts on long ones. I caught it before opening the PR, because Johnny’s #2420 feedback had me re-deriving each choice against the FA2 reference; flash_attn/src/dropout.h showed the seed was (row, col)-derived. Rewrote, validated forward and backward against PyTorch dropout with matched seeds, then filed.
A crowded space. I wasn’t the only person in flash-attention’s SM120 corner. sisgrad filed #2406 with a TMA forward overlapping my #2349; others (#2404, #2416, Johnny’s #2420) were submitting overlapping fixes. The PRs that merged fast were clean ports of well-understood patterns; the ones still open are doing harder work and need more review. Some of mine may get superseded by other contributors’ work, which is a normal and fine outcome in a healthy space, not a loss.
Phase 4 — the long-tail merges (April–May)
Three PRs from this stretch each took more than two months, and together they answer a question worth answering: what is the typical wait when contributing upstream to the open ML stack? Across the 14 direct merges the median is 4.5 days, but the distribution is bimodal. Seven merged in three days or fewer (small fixes that fit a known pattern); five took 28 days or more (kernel correctness, language features, external CI); almost nothing in between. The shape is two modes, fast for surgical fixes and slow for anything touching review depth or external CI, not a long tail.
flashinfer#2689 — ten bugs, then correct. FlashInfer had an SM120 XQA MLA decode kernel for FP8. A BF16 variant (#2675) compiled, ran, and produced 100% NaN on every config. Not subtly wrong, total garbage. I validated csrc/xqa/mla_sm120.cu config by config against flashinfer.mla_decode_paged and found ten separate bugs, none of which alone would produce non-garbage output. I bundled them into #2689.
Before: 100% NaN on every configuration. After the ten fixes: 0 NaN,
max_diff< 11 micro-units, 12 of 12 configs passing.
The ten:
Missing
MLA_BF16preprocessor flag, so the kernel compiled withINPUT_ELEM_TYPE = FP8.gen_xqa_module_mla()had FP8-only JIT assertions blocking BF16 compilation.Q tensor map hardcoded a 64B swizzle; BF16 needs 128B (
partElemsK=64 × 2 bytes).V tensor map 256-byte box exceeded max swizzle; reduced
partElemsVto 64.Consumer
ldmatrix.b8transpose scrambled BF16 elements; replaced with.b16transpose.Consumer out-of-bounds access on rows 16–47 in a 32-row buffer; restructured the BF16 consumer V load.
V buffer 4-part split incompatible with the single-part consumer.
Register pressure caused a stack overflow; reduced buffer counts.
storeOrderedXToShmBf16had OOBWarpAccindexing; rewrote with the correct MMA register mapping.Q register prefetch guard
idxAtomBx2 == 2never fired (tileNbAtomBx2 = 2means the range is0..1), so the Q registers stayed uninitialized and the first GEMM consumed garbage. Fixed withconstexpr auto qPrefetchAtomBx2 = min(2, tileNbAtomBx2 - 1).
Two of those show different shapes of “subtle.” Bug #3 (the swizzle) loads correctly-addressed bytes into wrong SMEM positions, so every downstream MMA sees scrambled inputs. Bug #10 is a guard that never triggers rather than a wrong instruction, which is the kind that produces clean-looking garbage. After all ten, validation across batch × seq_len ∈ {1,2,4} × {128,256,512,1024}produced zero NaN with max_diff under 11 micro-units, all twelve configs passing.
Filed March 4, merged May 7, 64 days. The wait was NVIDIA-internal CI. qsang-nvshepherded it through the internal GitLab CI mirror with repeated /bot runcycles, each taking days; saltyminty did the code review and naming alignment; jimmyzho handled the JIT side. The ten fixes were one file fixing one kernel and had to land together, so the calendar was driven by the slowest single piece.
triton#9572 started as a 30-line ergonomic change to the @aggregatedecorator and ended as a language-feature PR with an embedded PEP 649 bug: on Python 3.13, annotations are stored as strings until resolved, and Triton’s _resolve_aggregate_fields read __annotations__ directly and crashed. The vLLM Qwen3.5-9B bring-up on the Spark, our exact setup, was what surfaced it. The fix is one resolution call; finding the right shape took eight rounds with peterbell10, and along the way I closed an immutability gap (post-construction __setattr__ now raises) and a broken super().__post_init__() chain. Filed February 25, merged May 8, 72 days. Peter merged it with his own polish on top.
vllm#35568 — the always-True check. #35568 looked like a one-line fix: if get_device_capability() not in [89, 120]: return False. On SM121 it returned True, but it also returned True on SM120 and SM89 and everything else. DeviceCapability is a NamedTuple whose __eq__ returns NotImplemented against non-DeviceCapability types, so cap == 89 falls all the way through to identity and is False on every platform. The check had been silently disabling FP8 dispatch everywhere it was used, including at Marlin codegen time, which had been compiling kernels for the wrong arch set since the check was written. The fix routes eight call sites through is_device_capability_family(120). Filed February 28, merged May 15, 76 days, most of it wait. The part worth keeping: DavRodSwede noted on May 10 that the patch had been shipping in eugr/spark-vllm-docker since April 2, about 38 days of DGX Spark community deployment, plus a separate three-node Spark cluster on it. The patch was in production before it merged.
CUTLASS #3030 — the kernel
cutlass#3030 is the biggest open piece: a BF16 + FP8 CuTe DSL Flash Attention v2 for SM120 with CpAsync and TMA variants. As far as I could find, CUTLASS had no flash attention example for Blackwell GeForce before this. 10/10 correctness configs pass; the best I measured was 41 TFLOPS BF16 on SM121a.
NVIDIA’s Aneureka gave functional approval on April 28, flagging that FP8 TMA was about 20% behind BF16 in their repro and asking to narrow the gap, while noting they were open to merging first and following up on perf. depaulmillzreviewed COMMENTED rather than APPROVED, so the UI badge is BLOCKED. The kernel is acknowledged functional; the bottleneck is process, the same NVIDIA-OSS pattern as #3082/#3084, where the kernel may land in a wheel before it lands as a public merge.
Dead ends and absorbed PRs
Two investigations resolved to “not fixable here,” which is worth recording. flashinfer#2655 asked whether the BF16 MLA decode kernel could be extended to SM120 the way the FP8 path was; the answer is no, because the SMEM layout is designed around FP8’s 1-byte compactness. BF16 doubles grainsPerPartK and pushes Q+K+X to 193 KB against SM120’s 99 KB budget (the XVBuffer pad goes negative). There’s no version that fits without a full redesign; the FA2 backend is the working fallback, and I documented the analysis on the issue rather than filing a PR I couldn’t ship. vllm#35323 (Qwen3.5-MoE support) I closed prematurely assuming upstream support existed; parkerisme confirmed it still failed. It needs our patches; re-filing while the upstream backend selection is in flux would just create noise, so it’s on the active list rather than re-opened.
A few PRs were absorbed rather than merged directly: #2268/#2325 into the #2329/#2330/#2333 split, and flashinfer#2561 (an early CuTe DSL backend attempt) into jimmyzho’s merged #2446. Counting only direct merges undercounts the shipped work.
Who showed up
A few people did a lot of the load-bearing work on the other side of these PRs. b8zhong’s first correction on #18748 is what set the whole approach straight, and he reviewed several later SGLang PRs. tridao merged the SM120 forward/backward/varlen series and asked for the split that made it clean. johnnynunez was the most engaged reviewer across the effort: he found real bugs in the merged kernels, filed the dropout issue that became #2439, and kept tridao’s context warm. On the FlashInfer side, jimmyzho, yongwww, and yzh119 merged the dispatch work, and qsang-nv and saltyminty carried #2689 through internal CI and review. peterbell10 spent eight rounds getting the Triton PR right. I’m grateful to all of them; none of the merges happen without the reviewers.
June note: the ecosystem caught up
A month after the above, the picture moved in a way worth recording honestly, because it’s the part that matters most.
In early June a community contributor, thad0ctor, opened flash-attention#2634, an 8,500-line FA4 consumer-Blackwell integration. It builds on the merged #2329/#2330 foundation (the PR credits them and ships the #2349 TMA kernel close to verbatim) and does the integration the in-flight kernels were each reaching for separately: public-API routing, paged-KV, split-KV decode, an fp8 KV-cache decode kernel we never wrote, and a batch of correctness fixes. Several of our open PRs (split-KV #2336, paged #2348, TMA forward #2349) are superseded by it.
That’s not a loss to be defensive about; it’s the system working the way upstream contribution is supposed to. We laid the foundation, it was good enough to build on, and someone built on it, with the credit chain intact. It also left us holding the one thing only we could provide: the hardware. #2634 was developed on an RTX PRO 6000 (sm_120). The other consumer-Blackwell variant, DGX Spark / GB10 / sm_121a, is the one our stack runs on and the one the original kernels were written against.
So we validated it on the Spark. All 142 of #2634’s SM120 tests pass, plus independent checks against an fp32 reference (forward and backward through head_dim 256, varlen, paged-KV bit-identical to the dense kernel, torch.compile parity). On bandwidth, the decode path holds 82–84% of the GB10’s 273 GB/s unified-memory roofline.

FA4 decode on DGX Spark (GQA4, bf16), measured on our GB10: 224–229 GB/s across sequence lengths, 82–84% of the 273 GB/s unified-memory roofline. fp8 KV decode is about 1.9× over bf16; the SM120 suite and block-sparse cases pass on sm_121a. Best local figures I've measured, against other reported numbers where available.
We also surfaced two things the RTX PRO 6000 testing couldn’t: a test-gate (cc != (12, 0)) that silently skips the whole suite on sm_121 devices, and a head_dim > head_dim_v backward case that fails with a raw cudaErrorInvalidValue instead of a clean rejection. Both were reported with the validation. One note for any Spark user: upstream main still crashes on every FA4 call on sm_121a today, so for now #2634 is the difference between FA4 working and not working on that hardware.
The block-sparse forward (#2389) went the other way; it was still ours to finish. The reviewer, reubenconducts, had asked in March for it to match the SM90 design pattern. Working through that on current main surfaced a real constraint: SM90/SM100 drive block-sparse through warp-specialized producer/consumer helpers, and the SM80/SM120 forward is the Ampere cp.async pipeline, with no producer warp to run them. So the reworked version reuses the shared block-list model but runs a per-block load-compute, with the masking contract (including the first-full-block seqlen-masking case reuben flagged) matched to the warp-specialized path. The block-sparsity suite passes on sm_121a.
Two open PRs closed cleanly. #3082 closed because main shipped the equivalent change, the NVIDIA-wheel pattern this post described. #3106 (a Q_PAGED_KV gate) turned out to be a duplicate of our approved #3016, which carries the same change. One correction to the earlier narrative: the claim that SM12x→flashinfer routing “came in via #2598” was optimistic. On current main #2598 routes consumer Blackwell to a tcgen05/TMEM kernel that only runs on datacenter Blackwell, so the routing it added doesn’t work on sm_120/sm_121. The native path is #3016 (approved), and we’ve proposed superseding #2598 in its favor.
The through-line: the foundation was the durable part. PRs get superseded, duplicated, and occasionally turn out wrong on a closer look, but the merged SM120 kernels are what the ecosystem is building on, and having the actual sm_121a silicon is what let us be useful at the validation end, not just the authoring end.
What this work means for Second Nature Computing
We run training, fine-tuning, and serving on DGX Spark, so every open-source piece that didn’t work on SM121a was a piece of our stack that didn’t work. The cost-benefit on fixing upstream rather than carrying private patches is straightforward: a private patch is a recurring tax on every dependency bump, contributor onboarding, and CI rebuild; an upstream fix is paid once. The 76-day vLLM merge was a long wait, but at the end of it we no longer maintain that patch, and the community was running it before it landed.
As our footprint on this hardware grows, keeping up with these architecture gaps is ongoing work for us rather than a finished project. The shapes recur: exact-match arch checks proliferate faster than helper functions replace them, “Blackwell” gets treated as one architecture when it’s at least two, and AOT-wheel gaps turn pip install into “clone and build.” Where we can, the fix we reach for is shared infrastructure: is_family_of()-style helpers that scale to new sub-variants without code edits, and CI that covers at least one consumer Blackwell card. We expect to keep closing gaps like these as our compute needs scale.
In the next week I will be doing a write-up on an open-source kernel library I wrote and maintain, hand-written PTX targeting SM121, the optimization layer that grew directly out of this upstream work, since porting the stack is what showed us where the toolchains still fall short on this chip. If your team is working on consumer Blackwell (RTX 5090, RTX PRO 6000, DGX Spark) and hitting similar walls, I’d like to hear about it.
The community around this hardware is still small enough that knowing each other directly is useful blake@secondnaturecomputing.com.
